
Bulk Image Import File Format
Management Studio can be configured for Automated Indexing via Watched Folders. It is possible to use Watch Folders to import and Index multiple image files. To do this, you must create a text file which defines the Data Definition, the Index fields and their values and the files to be imported and Indexed. This chapter explains how to create this text file.
Licence required: Bulk Image Import requires a licence. If you do not see the options described here, contact support@mitratech.com about purchasing a licence.
Delimiters
Delimiters are mandatory.
The delimiter is set in Management Studio, in the Automated Indexing Options
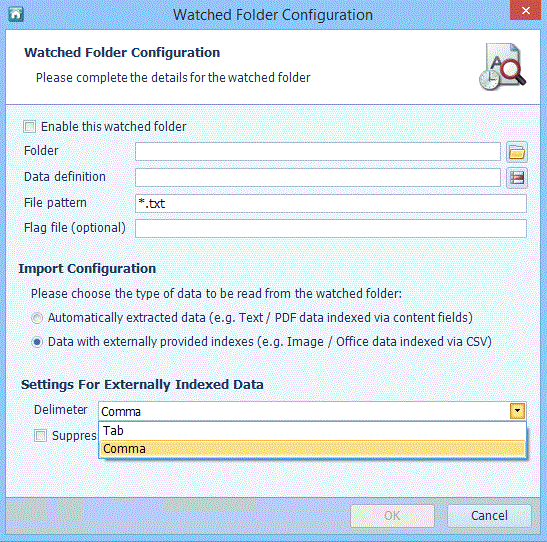
The entries in the text file can be delimited with a tab or a comma. When the Bulk Image Import parameters are configured in Management Studio, select the delimiter you will use in the text file. In this chapter, all examples use a comma delimiter. (See “Create Automated Indexing Options”.)
Header
The Header is mandatory.
The first line in the delimited text file is a case-sensitive header line describing the columns, for example:
"[Page number]","[Index set number]","Field 1","Field 2","Field 3","[Filename]"
This example defines the format of the Bulk Image Import file as:
- the first item on the line is the page number,
- the second item on the line is the index set number,
- the third item on the line is the Index value for the field named ‘Field 1’ in the selected Data Definition,
- the fourth item on the line is the Index value for the field named ‘Field 2’ in the selected Data Definition,
- the fifth item on the line is the Index value for the field named ‘Field 3’ in the selected Data Definition,
- the last item on the line is the name of the file to be indexed with the values given.
The Data Definition is specified in the Automated Indexing Options. See “Automated Indexing Options” for more information on the Automated Options and “Automated Indexing Watched Folders, Bulk Image Import” on for an example.
The columns may be specified in any order. However, the rest of the entries must follow the order you have defined in the header line.
Index Field Values
There is one column per Data Definition field, named with the Data Definition field name; so the above example is a Data Definition with three fields: Field 1, Field 2 and Field 3. Each index set row must include a value for at least one field. Document-level and Page-level index sets must be on separate rows: if a row contains values for both Document- and Page-level fields, an error occurs.
[Filename]
The [Filename] is mandatory.
The values in the [Filename] column are the names of the files to be imported. The paths may be absolute or relative to the watched directory. There may be more than one index set per file, i.e. more than one row with the same [Filename] value. Such rows must be consecutive.
The [Filename] column is mandatory and must have a value in every row.
The imported files are deleted upon successful import. Unsuccessfully-imported files are moved into the error directory corresponding to the Watched Folder.
[Index Set Number]
The [Index set number] is optional.
The values in the [Index set number] column define the index sets. It is permitted to have more than one row per index set; this is how multiple field values are specified for index sets.
Multiple field values must be on consecutive rows, for example:
"[Index set number]","Field 1","[Filename]"
1,"Value1","file-A.jpg"
1,"Value2","file-A.jpg"
2,"Value3","file-A.jpg"
defines two index sets for "file-A.jpg": one containing the values "Value1" and "Value2" and one containing the single value "Value3".
However:
"[Index set number]","Field 1","[Filename]"
1,"Value1","file-A.jpg"
2,"Value3","file-A.jpg"
1,"Value2","file-A.jpg"
is unsupported because the values for index set 1 are not on consecutive rows.
The [Index set number] column may be omitted; in this case, each row is taken to be a new index set. If the [Index set number] column is present, it must have a value in every row.
[Page Number]
The [Page number] is optional.
The values in the [Page number] column are the numbers of the pages with which Page-level index sets are associated. This is relevant for multi-page TIFFs. The [Page number] column may be omitted; in this case, the Page-level index sets are assigned to consecutive pages starting from page 1. If present, the column must have a value for every Page-level index set row and multiple index sets per page must be on consecutive rows. For Document-level index sets, the value of this column is ignored and may be left blank:
"[Page number]","Doc field","Page field","[Filename]"
,"Doc field value",,"file-A.tif"
1,,"Page 1 field value","file-A.tif"2,,"Page 2 field value","file-A.tif"
4,,"Page 4 field value","file-A.tif"
In the above example, page 3 has no index sets. The following text file contains an error:
"[Page number]","[Index set number]","Field 1","[Filename]"
1,1,"hello","file-A.tif"
2,1,"foo","file-A.tif"
because a single index set has been shared across two pages.
Behaviour
Successfully-imported image files are deleted unless they are read-only.
When you Bulk Import image files from Watched Folders using a CSV text file, the field values are validated. When the injection of one or more CSV rows fail, a CSV '_error' file with a CSV header and failed CSV rows is created in an error folder in each folder's respective '.Error' directory, so that users can manually rectify the field values and then return them to their Watched Folders for re-injection. If no errors are encountered, the delimited file is deleted.
Index Assistants are supported, provided that they do not require any user interaction: they must be triggered automatically and must not be configured to prompt the user if multiple index sets are returned.
Both Client and Server-side Index Assistants are supported and behave identically because the bulk image import runs server-side.